
Autonomous vehicles did not go from human-driven to self-driving overnight. Clinical AI follows the same progression. Each stage describes not only what the system can do, but how it learns to do it better.
A clinical AI lifecycle has four functions: Operate (run the conversation), Test (generate and run diverse scenarios), Evaluate (assess clinical standard compliance), and Improve (fix what is broken). At each stage, AI takes over more of these functions.
.png?width=608&height=341&name=side%20by%20side%20chart%20graphics%20(5).png)
We are now actively deploying Stage 4 capabilities for Q. The system corrects itself, but humans still validate. Q proposes improvements; humans verify them. Clinical governance is structural, not optional.
The distinction between Stage 3 and Stage 4 matters for operators evaluating clinical AI. Stage 3 systems, which include most tools currently on the market, execute single-step tasks and route to humans when those tasks complete. Stage 4 systems orchestrate adaptive, multi-step patient journeys end to end. They connect outbound and inbound, carry context across touchpoints, trigger downstream actions based on what the patient said, and route to human clinicians with full structured history intact. Q operates at this level today and is building toward the fully autonomous evaluation capabilities that complete the Stage 4 picture.
Decomposed Pipeline
Many AI voice platforms are converging on speech-to-speech models: a single neural network that ingests audio and produces audio. Elegant, but problematic for clinical applications. A monolithic model is a black box. A clinical reasoning failure cannot be isolated from a speech recognition error. Policies cannot be enforced at specific decision points. One component cannot be swapped without retraining the entire model.
Q decomposes the interaction into independently observable stages: speech recognition, clinical reasoning, response planning, language generation, and speech synthesis. Each stage has its own audit trail, governance controls, and upgrade cadence. The result is granular traceability, component-level governance, and auditability by design.
A single conversation turn completes in approximately 1.8 seconds. Within that window, audio is ingested via SIP, noise-cancelled, streamed through speech-to-text, analyzed by an end-of-utterance model, routed through retrieval-augmented generation to determine whether the answer lies in the LLM, the EHR, client files, or clinical protocols, processed by the clinical reasoning engine and approximately 20 concurrent guard agents in parallel, validated at the edge, synthesized to speech, and delivered back to the patient. Every stage produces structured audit data. Every guard agent intervention is logged. Every conversation turn feeds the self-healing cycle.
You cannot self-heal what you cannot observe.
.png?width=701&height=393&name=1-8%20cycle%20graphic%20(1).png)
Foundation-First
Rather than fine-tuning a model per workflow, Q uses foundation models for what they already excel at: natural conversation, complex instruction following, and medical context understanding. Specialized parallel guard agents handle the clinical-critical functions.
Safety detection agents are purpose-built classifiers for risks like suicide, self-harm, and abuse, where precision must exceed what general prompting can guarantee. Clinical variable extraction agents are trained extractors for medication names, dosages, symptom descriptions, and dates, with near-perfect accuracy. Compliance guard agents are rule-based and ML-hybrid systems enforcing regulatory requirements, consent flows, and escalation protocols in real time.
The foundation model handles the conversation. The guard agents handle clinical governance, running concurrently and intervening when clinical stakes demand it.
Each additional journey costs less than the previous one, because it inherits all guard agent improvements that prior deployments generated. Fine-tuning: 2x workflows equals 2x effort. Foundation-first: 2x workflows at a fraction of the marginal cost.
[visual callout box] "Fine-tuning: 2x workflows = 2x effort. Foundation-first: 2x workflows at a fraction of the marginal cost."
Three Audit Layers
Layer 0: Raw Signal. Every conversation produces a real-time transcript, metadata, and clinical outcome.
Layer 1: AI Auditors. Specialized post-processing models evaluate every conversation automatically: voicemail detection, safety escalation triggers, opt-out identification, clinical symptom mentions. Each writes a structured audit label.
Layer 2: Human Calibration. Clinical auditors review Q's assessments. When an automated label is incorrect, the correction becomes a high-precision training signal. An auditor reviewing AI labels is 5 to 10 times faster than reviewing raw conversations. Q pre-structures the analysis.
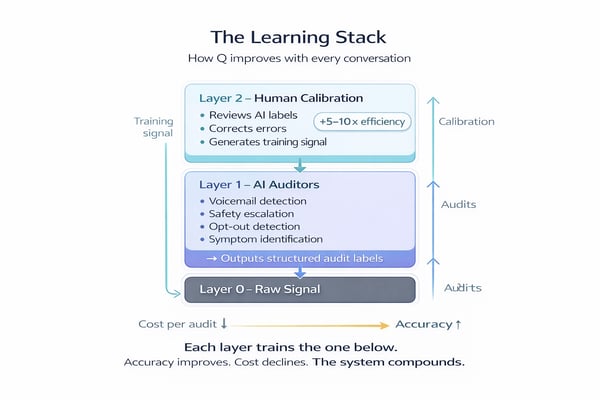
Each layer trains the layer below. Human corrections improve automated auditors. Better auditors reduce human workload. The system converges toward accuracy. The cost per audit converges toward zero.
Journey Orchestration
The self-healing architecture powers each conversation. The journey orchestration engine wires those conversations into complete care pathways.
Healthcare operations are not a sequence of independent tasks. A post-discharge follow-up that surfaces chest pain becomes an urgent nurse escalation. A chronic care check-in that reveals medication non-adherence triggers a pharmacist consult, a schedule adjustment, and a follow-up in 48 hours. Q models this as a directed acyclic graph where every node can branch, escalate, pause, retry, or complete based on what the patient said.
Three concerns that are typically collapsed into one are separated here.
The Journey Layer manages clinical logic: what journey this patient is in, what has happened, and what should happen next. Each journey is composable. Common patterns become reusable building blocks. A new care journey can be assembled from proven components in two hours from clinical brief to live deployment.
The Task Layer manages delivery: channels, retry logic, escalation paths, scheduling windows, and skills-based routing. A 78-year-old Mandarin-speaking patient who has declined AI calls three times needs a Mandarin-speaking nurse with full clinical context. The Task Layer makes this routing decision before a single call is placed. Every interaction, AI or human, produces an auditable trail.
The Agent Layer is the self-healing conversational engine described in the Decomposed Pipeline and Foundation-First sections above. Every conversation outcome feeds back into the journey, informing the next step.
.png?width=711&height=400&name=task%20to%20journey%20(1).png)
Five core step types structure every journey Q runs in production: tasks, sub-flows, waits, conditions, and goal checks. Each is composable, reusable across health systems, and validated against the full range of clinical scenarios the platform has encountered. Together, they give clinical teams a common language for modeling care pathways without starting from scratch for every deployment.
Data Governance, Event Streaming, and EHR Integration
A clinical AI platform that cannot guarantee data privacy at every stage of the pipeline has no business operating at scale. Sensitive data is classified at the point of ingestion, governed through retention policies, anonymized via generalization hierarchies validated against re-identification thresholds, and disposed of through cryptographic erasure. Privacy is not a feature. It is a property of the pipeline.
The journey engine is event-driven. HL7 FHIR R4 event streams from electronic health records, including discharge events, lab results, medication changes, and ADT messages, fire directly into the orchestration layer. When a patient is discharged, the post-discharge follow-up begins without a human touching a spreadsheet. Inbound and outbound events flow through the same layer, maintaining a single longitudinal patient context across every touchpoint.
Every patient interaction generates data. That data strengthens safeguards, validates behavior, and trains the evaluation engine. Better data produces better agents. Better agents earn clinician trust. Trust drives adoption. Adoption increases volume. Volume accelerates the cycle.
This is Jevons Paradox applied to healthcare. When the cost of delivering each clinical interaction falls, the economically viable volume of care expands. Increased healthcare consumption, when directed at prevention, early detection, and chronic disease management, reduces total system cost.
Two independent improvement curves drive this effect. The first is exogenous: every 12 to 18 months, frontier models become more capable, with better reasoning, better empathy, and longer context windows. In a foundation-first architecture, these improvements flow into every journey the moment the model is upgraded. The second is endogenous: every conversation generates labeled data, every audit campaign produces corrections, and every correction improves the next model. A safety model trained on cardiac follow-ups also improves safety detection in mental health triage, because guard agents are shared across journeys.
Fine-tuning is supervised learning: fixed datasets, one-shot training, no production signal. It operates on a linear curve. Foundation-first with continuous audit feedback is reinforcement learning: every conversation is a training episode, every human correction is a reward signal, and every improvement compounds across every journey. The result is 2x workflows at a fraction of the marginal cost of the first, because each new journey inherits every lesson the platform has ever learned. The gap between these two approaches widens with every conversation processed and every journey deployed.

These results are drawn from current production deployments, human-audited across 13,865 patient-facing sessions:
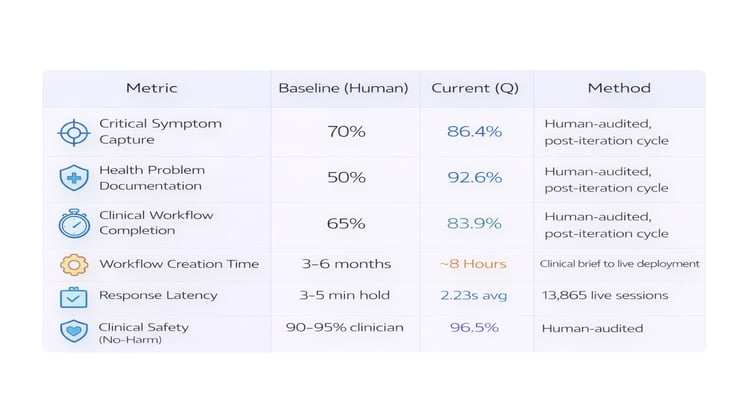
Note: Post-iteration cycle metrics. Measured on conversations following the first improvement cycle, consistent with the headline numbers in the Executive Summary. Live 90-day averages across all agents will vary as new agents enter their first iteration.
For full methodology and benchmark comparisons against published peer-reviewed research on telephone-based clinical practice, see the companion paper, Earning Autonomy: Q's Clinical Performance Validation.
Q operates live patient-facing deployments across the US and UK. In production, 39.8% of qualifying conversations are fully audited by clinical experts, a rate that is only feasible because of the layered audit architecture described above.