
- Part I: Abstract
- Part II: Why We Are Building Q
- Part III: What We Are Building
- Part IV: The Challenge of Autonomous Clinical AI
- Part V: How Q Addresses These Challenges
- Part VI: Validation: Earning Automation Through Evidence
- Part VII: Results
- Part VIII: Q and Standard Care Delivery
- Part IX: Performance After Iteration
- Part X: Early Production Observations
- Part XI Looking Forward
- Part XII What These Results Demonstrate
- Part XIII: Limitations
- Part XIV: Closing the Gap
This paper presents Q, a comprehensive AI clinical assistant developed by Quadrivia that conducts autonomous, real-time multichannel clinical conversations with patients. Q operates not as a copilot, but as an independent clinical agent under clinician oversight. It is designed to handle the routine, repeatable clinical and administrative tasks that consume clinician capacity, freeing clinicians from administrative burden so they can focus on higher value care.
Hundreds of thousands of tests were conducted during Q's development, iterating on every aspect of its clinical conversation pipeline. Once ready for formal validation, over 20,000 clinician-based tests and audits were conducted. Of these, 6,000 formed a structured validation program where all metrics were measured systematically across 25 clinical workflows. Across six clinical quality dimensions, Q meets published clinician benchmarks for the delivery of routine clinical tasks.

Across three structural metrics targeting documented failure points in care delivery, Q demonstrates measurable improvement over standard practice rates, and after each iteration cycle, continues to close the gap further. Following the controlled validation, Q was deployed across 9 tenants covering live patient interactions for 3 clients. Over a 14-day observation period (N = approximately 4,200 interactions), key metrics continued to improve in the transition from simulated to real-world patient interactions.
.png?width=1214&height=683&name=logo%20side%20by%20side%20(2).png)
Q's performance is compounding with each cycle of data, and the pace of improvement is accelerating.
Q is a comprehensive AI clinical assistant purpose built for real world healthcare operations: a hybrid managed service that combines the speed, scale, and cost efficiency of AI with the oversight and judgement of human clinicians to deliver the entirety of a healthcare organization's needs at a fraction of current cost.
No single agent, human or AI, completes 100% of a clinical task independently. In practice, a nurse may complete 60 to 70% of a workflow before handing off to a colleague for review, escalation, or specialist input. Q is designed around this same principle. It executes the structured, repeatable elements of clinical and administrative workflows at scale, so that when a clinician steps in, the groundwork is already done and they can focus entirely on what requires human judgement. Clinicians are not removed from the process; they are freed to focus on less repetitive and more meaningful clinical work.
Q engages patients across voice, SMS, and web, and maintains longitudinal care through continuous follow-up, monitoring, documentation, and escalation, all under clinician oversight. The challenge, and the focus of this paper, is demonstrating that an autonomous clinical agent can deliver care at the standard patients and clinicians expect. A detailed description of Q's architecture is presented in a companion technical paper.
Most clinical AI today operates as a copilot, a tool that assists clinicians rather than acting independently. Scribes transcribe. Chatbots answer questions. Decision support tools suggest next steps. These systems get clinicians part of the way there, but a human must fill every gap, verify every output, and complete every interaction. That model works in well staffed health systems with clinicians available to supervise each step. It does not scale to the half of the world's population that has no clinician available at all.
Q does something fundamentally different. It conducts autonomous, real time multichannel conversations with patients, not assisting a clinician during an interaction, but conducting the interaction itself, independently, under clinician oversight. This is a categorically harder problem than copilot AI, and it is the problem that must be solved if AI is to meaningfully address the global healthcare workforce gap.
WHY AUTONOMOUS CLINICAL CONVERSATION IS HARD
When a patient engages with Q, it must do what a trained clinician does: listen, understand, ask the right follow-up questions, capture clinical details accurately, follow the correct protocol branch, detect safety-critical signals, and respond with appropriate empathy, all in real time. Every step in this process must complete within approximately 1.8 seconds or the conversation feels unnatural and the patient disengages.
.png?width=793&height=445&name=1-8%20cycle%20graphic%20(1).png)
This is not a simplified pipeline. Each stage involves distinct engineering challenges: speech recognition must handle accents, background noise, and fragmented phrasing. Clinical reasoning must track state across dozens of conversational turns without losing critical details. Safety classification must catch life threatening signals in real time, not in post-hoc review.
The difficulty compounds because foundation models, the large language models that power modern AI, are not sufficient for this task on their own. When evaluated through realistic multi-turn patient conversations rather than structured case vignettes, LLM diagnostic accuracy drops significantly, from 82% to 62.7%, a 19.3 percentage point decrease (Johri et al., 2025). A systematic review of 39 clinical LLM benchmarks confirms this knowledge-practice gap is pervasive, with performance falling from 84 to 90% on knowledge-based tests to 45 to 69% on practice-based assessments (Gong et al., 2025). Due to the non-deterministic nature of LLMs, information that appears in the middle of a long input is more likely to be lost compared to information at the beginning or end (Liu et al., 2024). In a clinical conversation, a key symptom might be mentioned once, casually, several minutes into the conversation. If the model fails to retain it, that is not a theoretical limitation, it is a safety-critical failure mode.
Scaling clinical support is only valuable if safety can be demonstrated through evidence. Nothing is automated by default. Automation is earned through rigorous testing, validation, and proof.
Our testing approach uses a Swiss cheese model, a safety framework adopted in healthcare where no single layer is expected to catch everything, but the combination of overlapping layers ensures that failures in one are caught by another:
Automated testing: Unit tests, integration tests, and regression suites catch technical defects
AI-to-AI validation: Automated consistency checks identify behavioral drift; escalation scenarios verify detection rates
Internal human and clinician-based testing: All new workflows are tested with human testing using clinical vignettes before any patient exposure
Clinical review: Registered nurses audit conversations for medical accuracy and safety
Real-world monitoring: Post-market surveillance of workflows and audited patient interactions by registered nurses
Hundreds of thousands of tests were conducted during Q's development to refine and improve core functionality. Once ready for formal validation, over 20,000 clinician-based tests and audits were conducted. Of these, 6,000 formed a structured validation programme where all nine metrics were measured systematically across 25 clinical workflows spanning six categories: post-procedure follow-up, chronic condition management, preventive care and screening, mental health, rehabilitation and recovery, and pre-procedure preparation.
Trained human role-players conducted live conversations with Q, simulating realistic patient interactions across a range of clinical scenarios. The program was executed by a multidisciplinary team comprising 90% clinicians and doctors, supported by engineers and AI scientists. Performance was evaluated against published benchmarks drawn exclusively from peer-reviewed research on telephone-based clinical practice.
Q was evaluated across 6,000 clinical conversations spanning 25 clinical workflows, drawn from a broader program of over 20,000 clinician-based tests and audits. Performance was measured across two categories: first, broad clinical quality dimensions benchmarked against published peer-reviewed research on telephone-based clinical practice; and second, metrics targeting documented failure points in standard care delivery where Q's architecture provides structural advantages. All performance data was generated within a clinician-overseen governance structure. Every result reported here reflects Q operating under active clinical oversight and accountability.
PERFORMANCE OVERVIEW
Performance was assessed across six clinical quality dimensions. To contextualize these results, we compared against published benchmarks drawn exclusively from peer-reviewed research on telephone-based clinical practice, the closest published analogue to Q's operating modality.
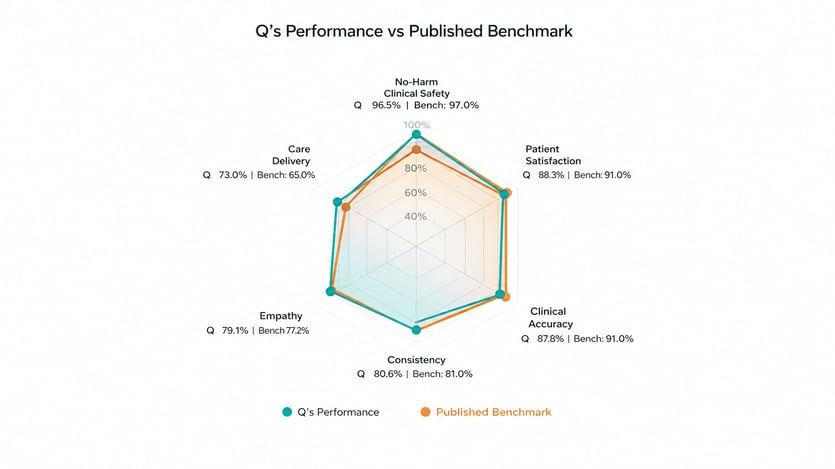
No-Harm Clinical Safety
No-Harm Clinical Safety measures the percentage of audited encounters with no potential for severe or fatal harm. Q achieved 96.5%, compared to a published clinician benchmark of 97% from a systematic review of telephone-based out-of-hours primary care across 4,934 encounters (Huibers et al., 2011). The same review found safety rates of 89% for high-urgency patients, underscoring that safety performance varies with clinical acuity. Q's mixed-acuity population makes the all-comers benchmark the most appropriate comparator.
The 3.5% of encounters that did not achieve a no-harm rating were not encounters in which patients were harmed. They are encounters where, under worst-case conditions, harm could theoretically have occurred. That distinction matters. Q's safety scoring system exists specifically to catch, classify, and learn from these signals before they can become failures. Every flagged encounter is reviewed and fed back into Q's improvement architecture.
It is also important to note that Q does not perform triage, a regulatory boundary that meaningfully limits the surface area where serious harm could realistically occur. The potential harm ceiling in our 3.5% is substantially lower than it would be in a system operating under triage scope. Our 96.5% rate exceeds the 92% industry standard in ambulatory care and sits within half a percentage point of the published telephone-based clinical benchmark. One hundred percent no-harm is achieved nowhere in healthcare. What this number tells you is that the system is paying attention, and getting better every time it is.

Patient Satisfaction
Patient Satisfaction reflects average satisfaction from post-call feedback, normalized to a 0 to 100% scale. Q achieved 88.3%, within the established range of 67% to 95% reported in a systematic review of patient satisfaction with telephone-based clinical consultations (O'Cathain et al., 2014). The benchmark midpoint from that review is 91%. Notably, Q's 88.3% falls within the range of normal clinician variation in that same review, where individual study results ranged from 67% to 95%.
Clinical Accuracy
Clinical Accuracy measures how accurately Q follows clinical protocols and provides correct clinical information during patient interactions. Q achieved 87.8%, compared to a published benchmark of 91% from a study evaluating the accuracy of telephone-based clinical assessments in out-of-hours primary care (Huibers et al., 2012). The 3.2 percentage point difference falls within the range of inter-clinician variability observed in comparable studies, where individual clinician accuracy varied depending on case complexity, time of day, and workload.
Consistency
Consistency measures how reliably Q follows the same clinical protocol across repeated interactions with similar presentations. Q achieved 80.6%, compared to 81% in a study measuring inter-rater agreement among nurses conducting telephone-based clinical assessments using standardized protocols (Belman et al., 2002). Unlike human-delivered care, Q's protocol adherence is architecturally enforced and does not degrade with volume, fatigue, or shift length.
Empathy
Empathy measures how empathetically Q communicates with patients, benchmarked against the patient-rated CARE measure, a validated 10-item instrument for consultation empathy (Sweeney et al., 2024). Q achieved 79.1%, compared to a benchmark of 77.2%. This is the one dimension where Q clearly exceeds the published clinician benchmark, suggesting that structured conversational design can deliver consistent empathic communication even without human intuition.
Care Delivery
Care Delivery measures the percentage of substantive conversations where Q delivered the intended care outcome, meaning the clinical or administrative objective of the workflow was completed. Q achieved 73.0%, compared to 65% in a study of nurse-led telephone follow-up programs where completion rates were limited by unreachable patients, incomplete calls, and staffing constraints (Harrison et al., 2014). Unlike human-staffed services, Q can reattempt engagement at scale across time zones and schedules, and each uncompleted interaction generates structured data on why it did not complete, enabling systematic improvement.
Beyond broad clinical quality, we assessed where Q's architecture addresses documented failure points in standard care delivery: missed critical symptoms, incomplete workflows, and undocumented patient health problems. These are not rare exceptions, nor are they measures of overall clinical practice. They are systemic gaps driven by time pressure, staffing shortages, and the practical limits of manual processes, precisely where structured automation provides a direct advantage.

Critical Symptom Capture Rate
Published data from nurse-led telephone encounters demonstrate that 22 to 36% of encounters omit critical symptom indicators due to gaps in assessment and documentation, with a midpoint of approximately 30% (North et al., 2014). This means roughly 70% of encounters capture critical symptoms adequately. Q achieved 84.6%, capturing critical symptoms at 1.2x the standard rate. This improvement is architectural: Q follows structured clinical protocols that systematically query for critical indicators, ensuring that essential symptoms are not skipped due to time pressure or conversational drift.
Clinical Workflow Completion Rate
Approximately 35% of clinical encounters in the same study contained major workflow or documentation defects (North et al., 2014). In standard practice, nurse-led telephone follow-up achieves completion rates of approximately 65% of attempted encounters (Harrison et al., 2014), with the remainder lost to unreachable patients, incomplete interactions, or staffing constraints. Q completed workflows at 70%, a 1.1x improvement. Unlike human-staffed services, Q can reattempt engagement at scale across time zones and schedules, and each uncompleted interaction generates structured data on why it did not complete, enabling systematic improvement.
Patient Health Problem Documentation Rate
In home healthcare, approximately 50% of patient health problems discussed during clinical encounters are not documented in the electronic health record (Song et al., 2022; Zolnoori et al., 2024). This documentation gap means that critical clinical information shared by patients is lost between encounters, creating risk for downstream care decisions. Q documented 69.5% of patient health problems, a 1.4x improvement driven by its architectural design where every data point is captured automatically through transcription and structured extraction. There is no reliance on a clinician remembering to document after the fact.
Q is a learning system. Every conversation generates data that feeds protocol refinement, sharpens clinical reasoning, and improves conversational performance. Following the initial validation, we conducted a targeted iteration cycle incorporating insights from the first 6,000 encounters, then re-evaluated performance on the same three structural metrics.

The improvements are substantial. Clinical Workflow Completion increased from 70% to 83.9%, a 13.9 percentage point gain that now exceeds the standard care delivery benchmark by 1.3x. Patient Health Problem Documentation rose from 69.5% to 92.6%, a 23.1 percentage point gain that now exceeds the benchmark by 1.9x. Critical Symptom Capture increased from 84.6% to 86.4%, extending its lead to 1.2x the standard rate.
These gains were achieved through a single iteration cycle. They demonstrate a fundamental property of Q's architecture: improvement is systematic, not incidental. Protocol refinements informed by real conversational data compound across every workflow that uses them. As the system scales and iteration cycles accumulate, performance will continue to improve.
Following the controlled validation program, Q was deployed across 9 tenants covering live patient interactions for 3 clients. Over a 14-day observation period (N = approximately 4,200 interactions), the transition from simulated to real-world patient interactions provided an opportunity to measure targeted metrics as part of ongoing post-deployment surveillance. Two metrics from the initial validation showed marked improvement.

No-Harm Clinical Safety increased from 96.5% to 98.4%, and Care Delivery Success increased from 73.0% to 82.3%. These gains reflect continued iteration informed by real-world conversational data across a broader range of clinical scenarios and patient populations than the controlled validation alone.
These observations are drawn from production data and represent a different measurement context from the controlled validation. Not all metrics from the initial validation were measured during this period; these two are reported because they were actively tracked as part of post-deployment surveillance. The remaining metrics from the broader quality framework continue to be monitored and will be reported in subsequent evaluations.
These benchmarks represent real-world clinician performance, not theoretical perfection. Clinicians working under time pressure, staffing constraints, and shift fatigue do not achieve 100% in any of these dimensions. Q meets that same real-world standard, consistently, at scale, and at a fraction of the cost. Across the three structural metrics targeting documented failure points in care delivery, Q exceeds standard rates in all three, and after a single iteration, exceeds them by a widening margin.

This establishes a critical proof point: a purpose-built AI clinical assistant can deliver care at levels comparable to trained human clinicians, validated across controlled and real-world settings. Early production observations confirm that these results hold and in key areas improve when Q transitions to live patient interactions.
Q's performance is compounding with each cycle of data. These results represent a baseline. They will improve with scale.
For the communities affected by the global health worker shortage, the question is not whether AI-assisted care meets every benchmark a well-staffed health system can achieve. The question is whether it can deliver safe, consistent, meaningful care where none exists today. The evidence presented here says it can.

Routine follow-up, structured screening, chronic condition check-ins, post-procedure monitoring: these are essential workflows that consume enormous clinical capacity and, in most of the world, simply do not happen. Q was built to change that. Not to replace clinicians, but to make their expertise reach further.
For healthcare organizations already operating with clinical teams, Q changes the economics. A hybrid model where AI handles structured workflows at scale and clinicians focus on complex assessment and decision-making delivers the full scope of a healthcare organization’s operational needs at a fraction of current cost. Not by cutting corners, but by allocating human expertise where it is irreplaceable and extending it everywhere else.
The results in this paper represent Q's first large-scale validation. As workflows expand, as real-world deployment compounds the data that drives improvement, and as iteration cycles continue to close the remaining gaps, the trajectory is clear.
The results in this paper show not just where Q is today, but how quickly it is getting there. The gap between what healthcare can reach today and what it must reach tomorrow: that is the gap Quadrivia was built to close.